
Descripción general del proyecto
Este repositorio contiene el código y los recursos necesarios para modelar una base de datos transaccional utilizando PostgreSQL. El objetivo principal es estructurar las entidades y relaciones a partir de un archivo de texto descargado de Kaggle, y luego poblar las tablas correspondientes mediante un stored procedure. En este proyecto, se han seguido los siguientes pasos para llevar a cabo el modelado y la carga de datos:
Recolección de Requisitos:
Diseño Conceptual:
Diseño Físico:
Implementación:
Pruebas y Validación:
Recolección y análisis de los datos
Para modelar una base de datos transaccional basada en los datos de los archivos .txt descargados de Kaggle, podemos seguir un proceso estructurado, desde la recolección y análisis de los datos hasta el diseño y creación de la base de datos
Entender los Datos
Es crucial comenzar por comprender la estructura y el contenido de los datos. Esto implica revisar las cabeceras y el formato de los archivos para identificar las columnas y tipos de datos que se manejarán. A continuación se muestra un ejemplo de cómo se ven las cabeceras de los datos en el archivo:
 Cabeceras de los Datos
Al revisar las cabeceras, podemos determinar qué tipo de información está contenida en cada columna y cómo se relacionan entre sí. Este paso es fundamental para planificar cómo los datos se modelarán en la base de datos. La siguiente imagen muestra un ejemplo detallado de las cabeceras y algunos datos de muestra:
Cabeceras de los Datos
Al revisar las cabeceras, podemos determinar qué tipo de información está contenida en cada columna y cómo se relacionan entre sí. Este paso es fundamental para planificar cómo los datos se modelarán en la base de datos. La siguiente imagen muestra un ejemplo detallado de las cabeceras y algunos datos de muestra:
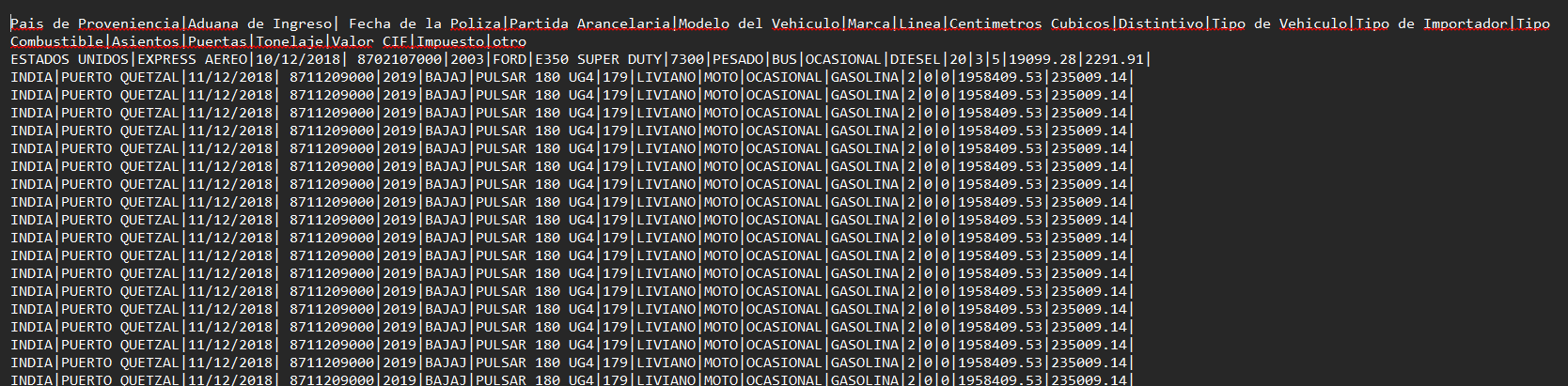 Las columnas identificadas en los datos son las siguientes:
Las columnas identificadas en los datos son las siguientes:
Características de los Datos:
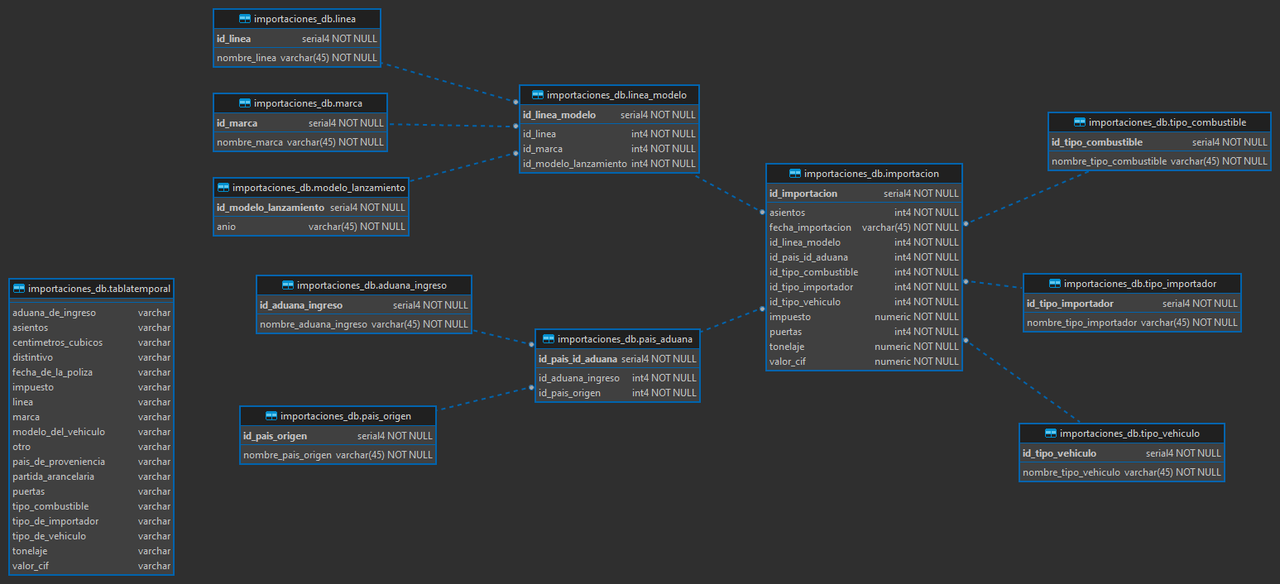
Modelo Físico OLTP
Creación de la Base de Datos
En esta sección se describen los comandos utilizados para la creación de la base de datos en PostgreSQL. Estos comandos se aplican a lo largo del desarrollo de la base de datos para definir esquemas, tablas, constraints y otras estructuras necesarias. Esta documentación sirve como referencia para entender y reproducir el proceso de creación de la base de datos.
Comandos Utilizados
CREATE SCHEMA: Se utiliza para crear un nuevo esquema en la base de datos, que sirve como un contenedor para las tablas y otros objetos. CREATE TABLE: Se utiliza para crear una nueva tabla dentro del esquema especificado. Define la estructura de la tabla, incluyendo las columnas y sus tipos de datos. COPY: Se utiliza para cargar datos desde un archivo externo a una tabla en la base de datos. SERIAL: Se utiliza para definir una columna de tipo entero que se auto incrementa automáticamente. Es útil para crear identificadores únicos. PRIMARY KEY: Se utiliza para definir una clave primaria en una tabla, que asegura la unicidad y no nulidad de los valores en una columna o conjunto de columnas. UNIQUE: Se utiliza para asegurar que los valores en una columna o conjunto de columnas sean únicos en la tabla. FOREIGN KEY: Se utiliza para definir una clave foránea en una tabla, que crea una relación entre columnas de diferentes tablas. Asegura la integridad referencial entre las tablas.
Stored Procedure para la Carga de Información
En el stored procedure creado para la carga de información, se utilizan diversos comandos y técnicas para asegurar una limpieza y una carga adecuada de los datos. A continuación, se describen los principales elementos y comandos utilizados:
Comandos Utilizados
UPPER: Se utiliza para convertir todos los datos a mayúsculas, asegurando así una homologación de la información. TRIM: Se utiliza para eliminar espacios en blanco al inicio y al final de los datos. UPDATE: Se utiliza para realizar una limpieza y actualización de los datos. Por ejemplo, en casos donde se detectó que la marca "GREAT DANE" estaba escrita incorrectamente como "RATE DANE". DELETE: Se utiliza para eliminar la información de las tablas antes de la ejecución del stored procedure, evitando así errores al momento de la población. INSERT INTO: Se utiliza para poblar las tablas con los datos limpios y estructurados. GROUP BY: Se utiliza para agrupar los datos de los catálogos al momento de la carga. ORDER BY: Se utiliza para ordenar los datos al momento de insertarlos, asegurando que las claves automáticas se generen en el orden correcto. LEFT JOIN e INNER JOIN: Se utilizan para poblar tablas que dependen de otras tablas de catálogo previamente pobladas, de manera que se puedan obtener sus llaves primarias. Bucle FOR: Se utiliza para recorrer los registros de la tabla temporal y, en la recursividad, extraer las llaves de cada catálogo para poblar la tabla base que contiene los registros de las importaciones.