Descripción general del proyecto
Este proyecto tiene como objetivo realizar análisis de datos directamente desde la fuente de datos utilizando consultas SQL. La base de datos está estructurada para almacenar información específica de importaciones vehiculares.Todo el proceso de modelamiento de datos se realizó en un proyecto anterior compartido en Git, el cual se puede encontrar Postgresq-modelado-y-carga-de-datos .
Preguntas Principales de Análisis:
Comandos SQL Utilizados en el Análisis
Para desarrollar y responder las preguntas de análisis planteadas en este proyecto, se han utilizado diversos comandos y técnicas SQL avanzadas. A continuación, se detallan algunos de los comandos más importantes empleados: SELECT El comando SELECT se utiliza para seleccionar datos de una base de datos. Es uno de los comandos más fundamentales en SQL. GROUP BY El comando GROUP BY se utiliza para agrupar filas que tienen los mismos valores en columnas especificadas en grupos. ORDER BY El comando ORDER BY se utiliza para ordenar el conjunto de resultados de una consulta SQL por una o más columnas. JOINs (LEFT JOIN, INNER JOIN) Los comandos JOIN se utilizan para combinar filas de dos o más tablas, basadas en una columna relacionada entre ellas. En este proyecto, se utilizaron LEFT JOIN e INNER JOIN para combinar tablas. EXTRACT La función EXTRACT se utiliza para extraer subpartes de una fecha, como el año o el mes. WHERE El comando WHERE se utiliza para filtrar registros que cumplen una condición especificada. SUBSTR La función SUBSTR se utiliza para extraer una subcadena de una cadena. SUBCONSULTAS Las subconsultas se utilizan para ejecutar una consulta dentro de otra consulta.
Descripción de Tablas y Relaciones
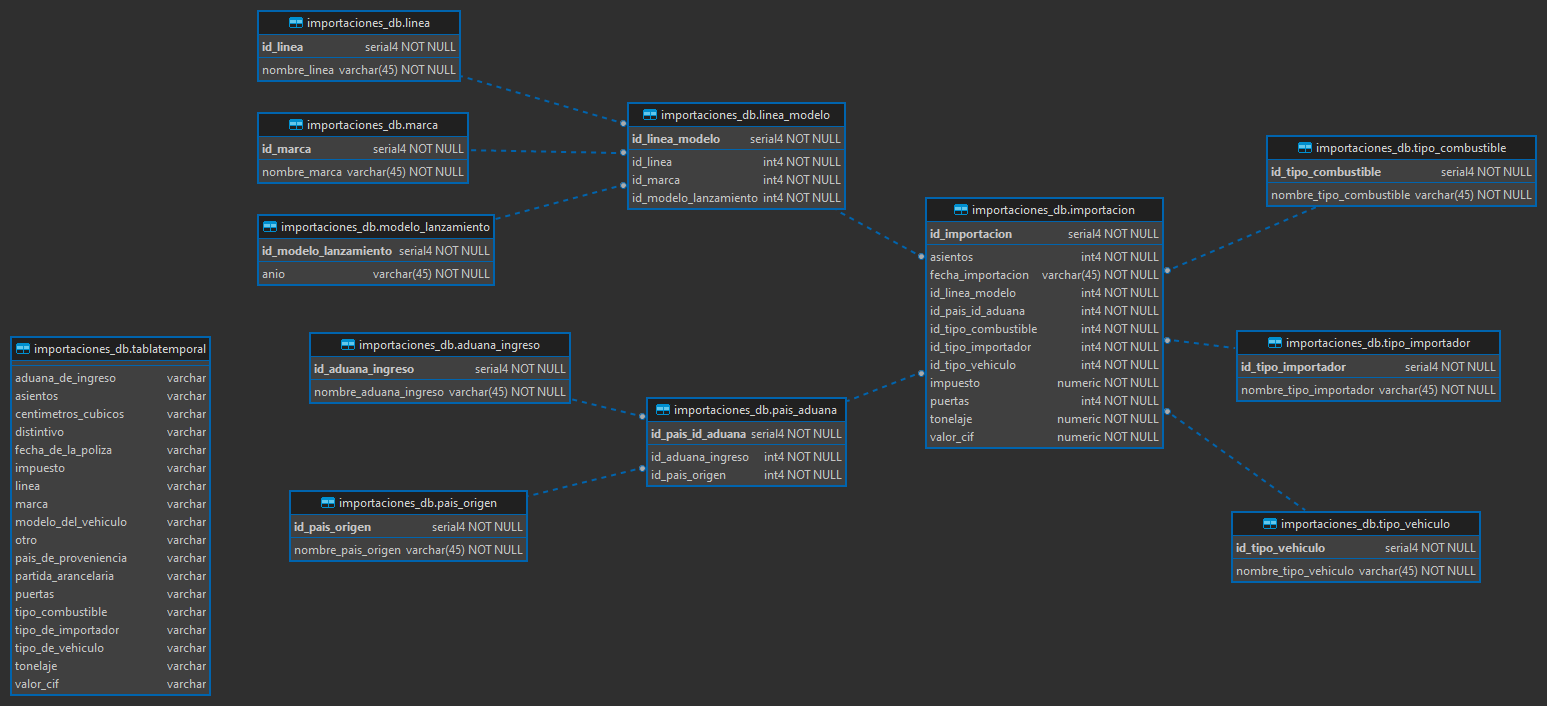
1. Tabla: importaciones_db.marca
Descripción: Contiene información sobre las marcas de los vehículos.
Columnas:
- id_marca: Identificador único de la marca (Clave primaria).
- nombre_marca: Nombre de la marca (Único).
Relaciones: Relacionada con importaciones_db.linea_modelo.
2. Tabla: importaciones_db.tipo_combustible
Descripción: Contiene información sobre los tipos de combustible de los vehículos.
Columnas:
- id_tipo_combustible: Identificador único del tipo de combustible (Clave primaria).
- nombre_tipo_combustible: Nombre del tipo de combustible (Único).
Relaciones: Relacionada con importaciones_db.importacion.
3. Tabla: importaciones_db.tipo_vehiculo
Descripción: Contiene información sobre los tipos de vehículos.
Columnas:
- id_tipo_vehiculo: Identificador único del tipo de vehículo (Clave primaria).
- nombre_tipo_vehiculo: Nombre del tipo de vehículo (Único).
Relaciones: Relacionada con importaciones_db.importacion.
4. Tabla: importaciones_db.tipo_importador
Descripción: Contiene información sobre los tipos de importadores.
Columnas:
- id_tipo_importador: Identificador único del tipo de importador (Clave primaria).
- nombre_tipo_importador: Nombre del tipo de importador (Único).
Relaciones: Relacionada con importaciones_db.importacion.
5. Tabla: importaciones_db.modelo_lanzamiento
Descripción: Contiene información sobre los modelos de lanzamiento de los vehículos.
Columnas:
- id_modelo_lanzamiento: Identificador único del modelo de lanzamiento (Clave primaria).
- anio: Año del modelo de lanzamiento (Único).
Relaciones: Relacionada con importaciones_db.linea_modelo.
6. Tabla: importaciones_db.linea
Descripción: Contiene información sobre las líneas de vehículos.
Columnas:
- id_linea: Identificador único de la línea (Clave primaria).
- nombre_linea: Nombre de la línea (Único).
Relaciones: Relacionada con importaciones_db.linea_modelo
7. Tabla: importaciones_db.pais_origen
Descripción: Contiene información sobre los países de origen de los vehículos.
Columnas:
- id_pais_origen: Identificador único del país de origen (Clave primaria).
- nombre_pais_origen: Nombre del país de origen (Único).
Relaciones: Relacionada con importaciones_db.pais_aduana.
8. Tabla: importaciones_db.aduana_ingreso
Descripción: Contiene información sobre las aduanas de ingreso de los vehículos.
Columnas:
- id_aduana_ingreso: Identificador único de la aduana de ingreso (Clave primaria).
- nombre_aduana_ingreso: Nombre de la aduana de ingreso (Único).
Relaciones: Relacionada con importaciones_db.pais_aduana.
9. Tabla: importaciones_db.pais_aduana
Descripción: Relaciona los países de origen con las aduanas de ingreso.
Columnas:
- id_pais_id_aduana: Identificador único de la relación (Clave primaria).
- id_pais_origen: Identificador del país de origen (Clave foránea).
- id_aduana_ingreso: Identificador de la aduana de ingreso (Clave foránea).
Relaciones:
id_pais_origen referencia a importaciones_db.pais_origen( id_pais_origen).
id_aduana_ingreso referencia a importaciones_db.aduana_ingreso( id_aduana_ingreso).
10. Tabla: importaciones_db.linea_modelo
Descripción: Relaciona las líneas de vehículos con los modelos de lanzamiento y las marcas.
Columnas:
- id_linea_modelo: Identificador único de la relación (Clave primaria).
- id_linea: Identificador de la línea (Clave foránea).
- id_modelo_lanzamiento: Identificador del modelo de lanzamiento (Clave foránea).
- id_marca: Identificador de la marca (Clave foránea).
Relaciones:
id_linea referencia a importaciones_db.linea(id_linea).
id_modelo_lanzamiento referencia a importaciones_db.modelo_lanzamiento( id_modelo_lanzamiento).
id_marca referencia a importaciones_db.marca(id_marca).
11. Tabla: importaciones_db.importacion
Descripción: Contiene información sobre las importaciones de vehículos.
Columnas:
- id_importacion: Identificador único de la importación (Clave primaria).
- id_pais_id_aduana: Identificador de la relación país-aduana (Clave foránea).
- id_linea_modelo: Identificador de la relación línea-modelo (Clave foránea).
- id_tipo_vehiculo: Identificador del tipo de vehículo (Clave foránea).
- id_tipo_combustible: Identificador del tipo de combustible (Clave foránea).
- id_tipo_importador: Identificador del tipo de importador (Clave foránea).
- fecha_importacion: Fecha de la importación.
- valor_cif: Valor CIF de la importación.
- impuesto: Impuesto sobre la importación.
- puertas: Número de puertas del vehículo.
- tonelaje: Tonelaje del vehículo.
- asientos: Número de asientos del vehículo.
Relaciones:
id_pais_id_aduana referencia a importaciones_db.pais_aduana( id_pais_id_aduana).
id_linea_modelo referencia a importaciones_db.linea_modelo( id_linea_modelo).
id_tipo_vehiculo referencia a importaciones_db.tipo_vehiculo (id_tipo_vehiculo).
id_tipo_combustible referencia a importaciones_db.tipo_combustible( id_tipo_combustible).
id_tipo_importador referencia a importaciones_db.tipo_importador( id_tipo_importador).
Modelo Físico OLTP
Contenido del Repositorio
El proyecto está organizado en los siguientes directorios:
querys.sql: Script con las consultas para cada pregunta de análisis.
Instrucciones para Configurar y Cargar los Datos
Capturas de Pantalla
Script SQL - Creación de Tablas

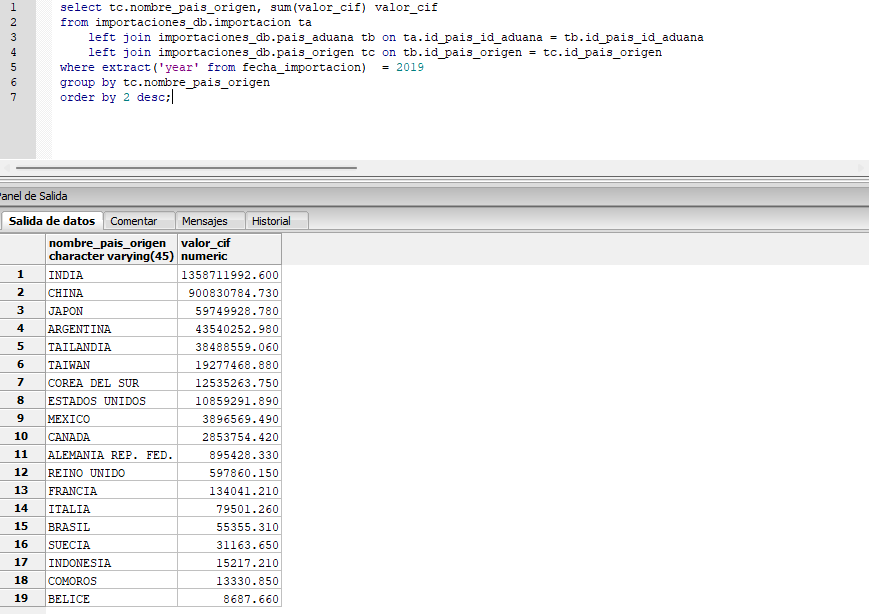
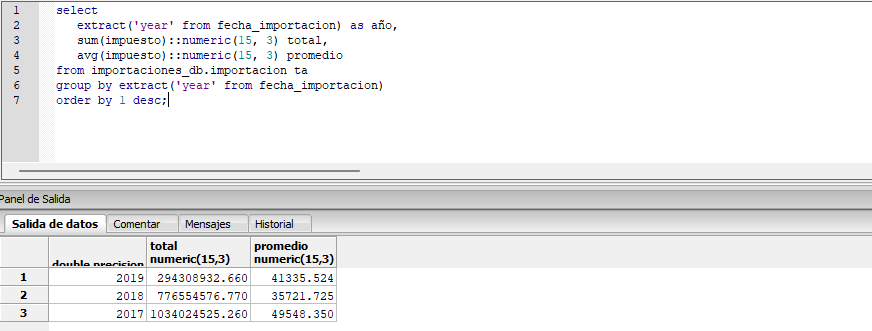
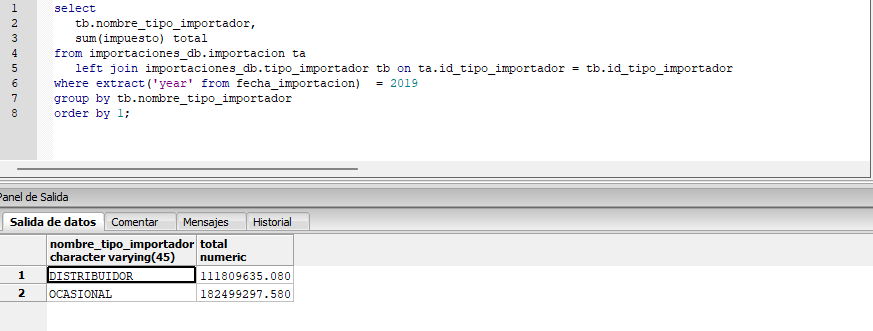
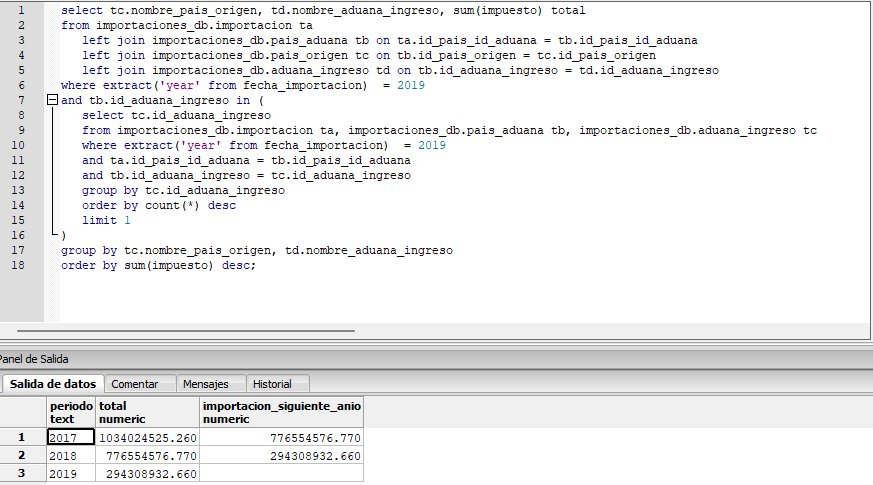
Análisis de Datos y Capturas de Resultados
Análisis de Datos y Capturas de Resultados
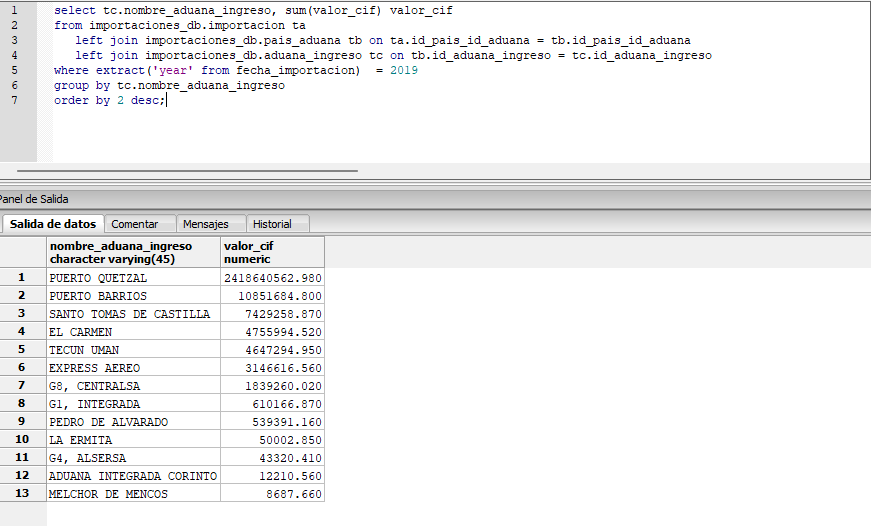
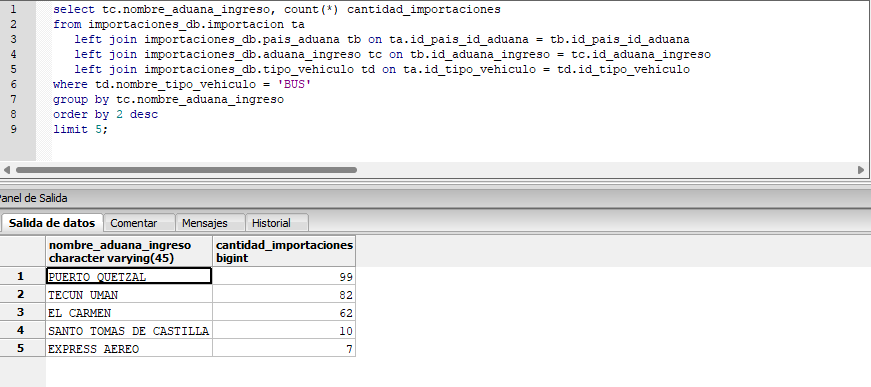
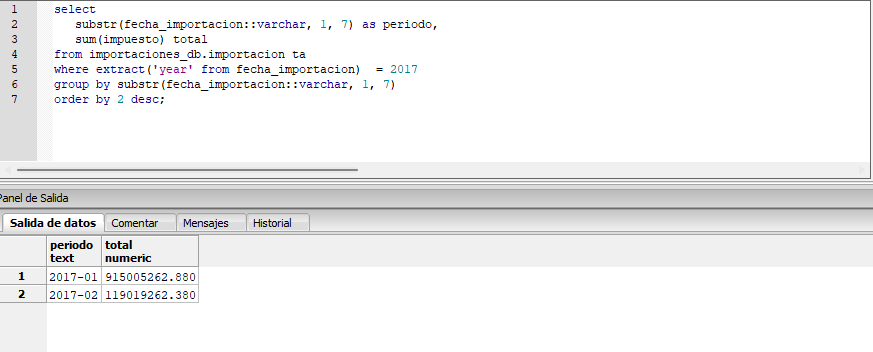
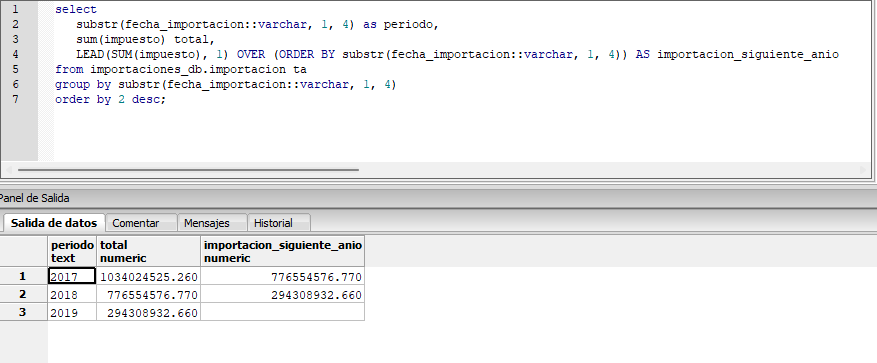
Repositorio del Proyecto en GitHub
Para obtener más detalles sobre cada uno de los pasos y configuraciones, junto con la documentación completa del proceso, puede visitar el Repositorio del Proyecto en GitHub, el cual contiene todas las fuentes necesarias para desplegar el proyecto.
