Descripción general del proyecto
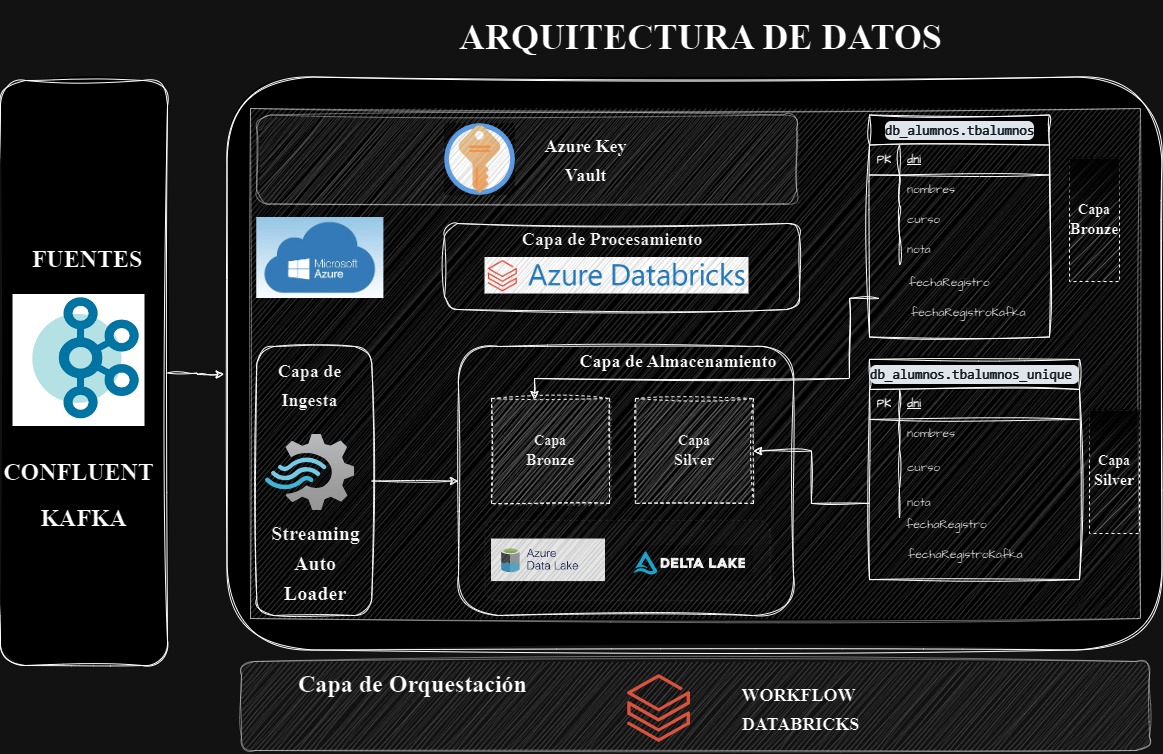
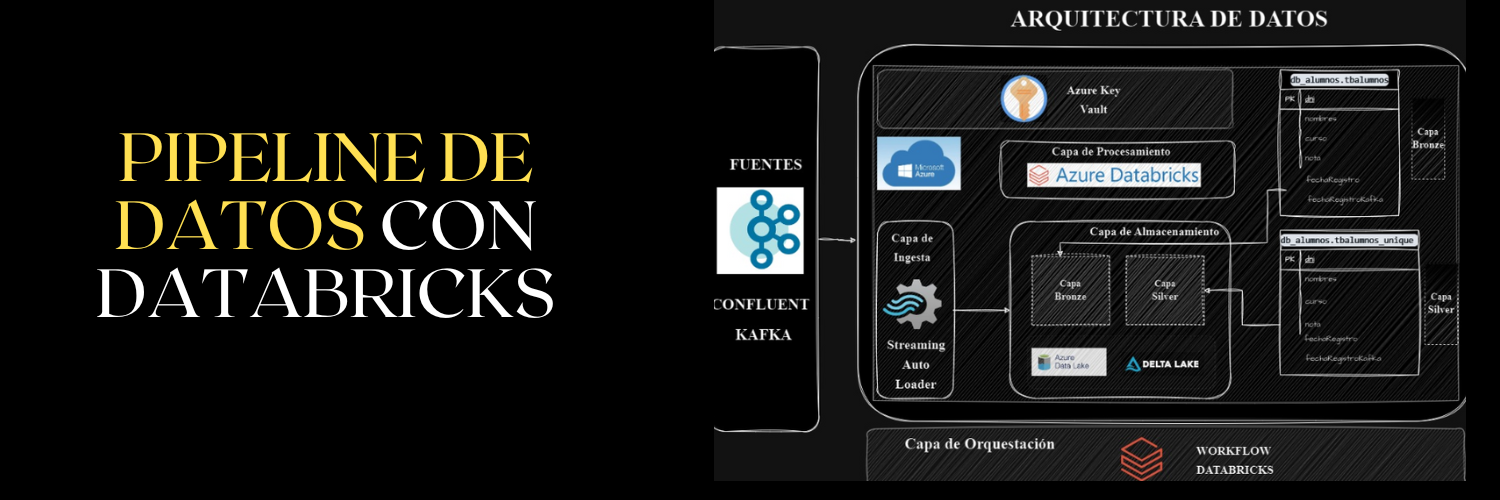
Este proyecto muestra la implementación de un pipeline de datos utilizando Databricks, Kafka y Delta Lake en Azure. El objetivo es demostrar cómo se pueden integrar diversas tecnologías para crear un flujo de datos en tiempo real, desde la generación de datos hasta su almacenamiento y procesamiento. El proyecto incluye la creación de una base de datos para almacenar información de alumnos y la simulación de datos ficticios de alumnos que se ingestan cada dos segundos en Kafka para simular un streaming, actualizando las tablas Delta Lake en tiempo real.
Este proceso se orquestará mediante un workflow en Databricks, configurado para que su ejecución sea automática. Además, se añadirán notificaciones en caso de fallos durante la ejecución para asegurar una supervisión constante y la rápida detección de problemas.
El pipeline se compone de tres notebooks principales:
Create_Database: El primer notebook del pipeline se encarga de crear la base de datos y las tablas Delta Lake. Utiliza la propiedad enableChangeDataFeed para permitir una auditoría de los cambios realizados en las tablas. Esto asegura que todos los cambios en los datos sean rastreados y puedan ser revisados posteriormente.
Producer_Messager: El segundo notebook genera datos ficticios de 100 alumnos de manera aleatoria. Utilizando un bucle, inserta estos datos en Kafka Confluent cada dos segundos, simulando así un flujo de datos continuo. Esta generación y envío de datos en intervalos regulares permite simular un entorno de datos streaming realista.
Streaming_Messages: El último notebook se encarga de leer los datos en tiempo real desde Kafka Confluent utilizando la funcionalidad readStream y registrarlos en una de las tablas Delta Lake. Utiliza el método writeStream para asegurar que los datos se escriban en streaming, permitiendo una actualización continua y en tiempo real de la base de datos.
Este enfoque integrado y automatizado demuestra cómo las tecnologías modernas pueden trabajar juntas para manejar flujos de datos en tiempo real de manera eficiente y confiable.
Tecnologías Utilizadas
Databricks
Databricks es una plataforma de análisis de datos unificada que simplifica y acelera la realización de tareas de big data. Utilizamos Databricks para:
Configurar y gestionar el entorno de datos.
Crear y gestionar bases de datos y tablas Delta lake.
Ejecutar procesos de ETL y análisis de datos en tiempo real.
Automatizar la ejecución del pipeline a través de jobs en Databricks.
Kafka
Kafka es una plataforma de streaming de eventos distribuida utilizada para la construcción de pipelines de datos en tiempo real. En este proyecto, Kafka se utiliza para:
Transmitir datos generados de manera continua.
Asegurar la entrega eficiente y escalable de mensajes de datos entre sistemas.
Delta Lake
Delta Lake es una capa de almacenamiento que añade fiabilidad a los data lakes. Con Delta Lake, podemos realizar:
Almacenamiento transaccional ACID.
Gestión eficiente de grandes volúmenes de datos.
Integración con Databricks para análisis y procesamiento de datos.
Azure Key Vault
Azure Key Vault es un servicio de gestión de secretos en la nube que permite almacenar y acceder a contraseñas, claves API y otros secretos de manera segura. En este proyecto, Azure Key Vault se utiliza para:
Gestionar las credenciales de Kafka de manera segura.
Integrar con Databricks a través de scopes para acceder a los secretos durante la ejecución del pipeline.
Cómo Ejecutar el Proyecto
Configurar Databricks
Crear un clúster en Databricks.
Configurar los secretos de Kafka en Azure Key Vault y crear un scope en Databricks para acceder a ellos.
Ejecutar los Notebooks
Ejecutar el notebook Create_Database para configurar la base de datos y las tablas.
Ejecutar el notebook Producer_Messager para generar y enviar datos a Kafka.
Ejecutar el notebook Streaming_Messages para consumir y procesar los datos en tiempo real.
Automatizar el Pipeline
Configurar y activar un job en Databricks para automatizar la ejecución de los notebooks en el orden correcto.
Verificar Resultados
Revisar las tablas tbalumnos y tbalumnos_unique en Databricks para ver los datos procesados.