Descripción general del proyecto
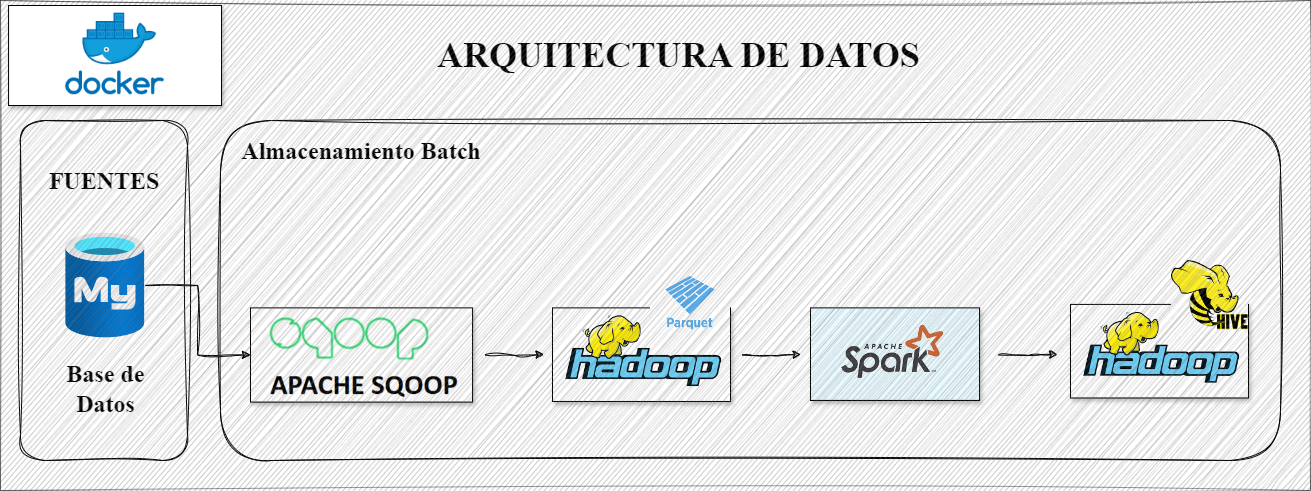
El proyecto de Importaciones Vehiculares tiene como objetivo analizar datos sobre las importaciones de vehículos, utilizando un conjunto de herramientas de Big Data para manejar y procesar grandes volúmenes de información. La fuente de datos proviene de registros oficiales de importaciones vehiculares, proporcionando detalles como el tipo de vehículo, el país de origen, la fecha de importación, y otros datos relevantes Justificación del Uso del Ecosistema Hadoop Para este proyecto, se ha elegido el ecosistema de Hadoop debido a sus capacidades robustas y escalables para el almacenamiento y procesamiento de grandes volúmenes de datos. A continuación, se describe cómo cada componente de este ecosistema contribuye a la solución:
Proceso General del Proyecto
A continuación, se describe el proceso general del proyecto, proporcionando una visión macro de las actividades realizadas: 1. Base de Datos Relacional en MySQL:
Estructura del Proyecto
BigData_Haddop/ │ ├── datanode/ │ ├── jdbc/ │ ├── scripts/ │ ├── sqoop/ │ └── Dockerfile │ ├── mysql/ │ └── Dockerfile │ └── importaciones_db.sql │ └── variables.env │ ├── python/ │ ├── source/ │ ├── source/ │ └── Dockerfile │ └── README.md └── docker-compose.yaml └── hadoop-hive.env
Instrucciones de Uso
Para utilizar este proyecto, sigue estos pasos:
git clone https:// github.com/jcarlosmamanidelacruz/ BigData_Hadoop
cd BigData_Haddop
docker-compose up
Este comando iniciará todos los servicios definidos en el archivo docker-compose.yaml.
Configuración de Visual Studio Code
Para facilitar la gestión de los contenedores Docker y la interacción con la base de datos MySQL, se recomienda instalar las siguientes extensiones en Visual Studio Code:
- Abre Visual Studio Code.
- Ve al menú de extensiones (Ctrl+Shift+X o Cmd+Shift+X en macOS).
- Busca "Docker Explorer".
- Haz clic en "Instalar".
- Abre Visual Studio Code.
- Ve al menú de extensiones (Ctrl+Shift+X o Cmd+Shift+X en macOS).
- Busca "MySQL".
- Haz clic en "Instalar".
- Crear un codespace para el repositorio e ingresar al mismo
- Abrir terminal de codespace
- Ejecutar el siguiente comando para desplegar los contenedores
docker-compose up
Esta linea desplegara los contenedores y podras ver estos utilizando la extension Docker explorer
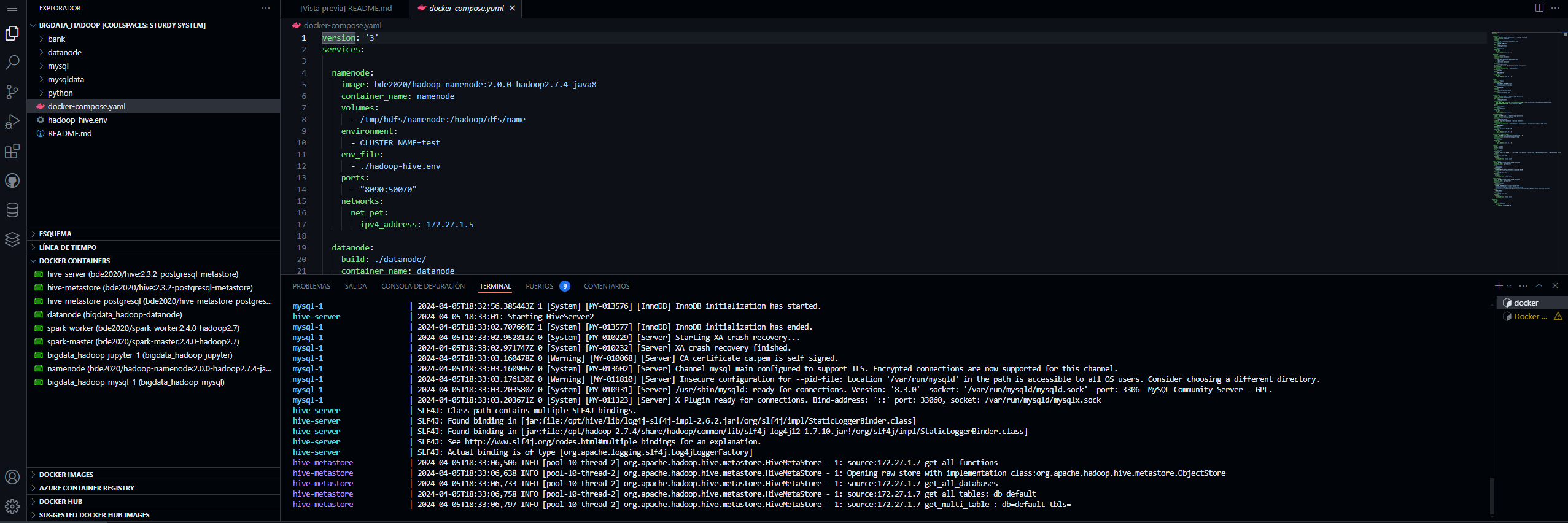
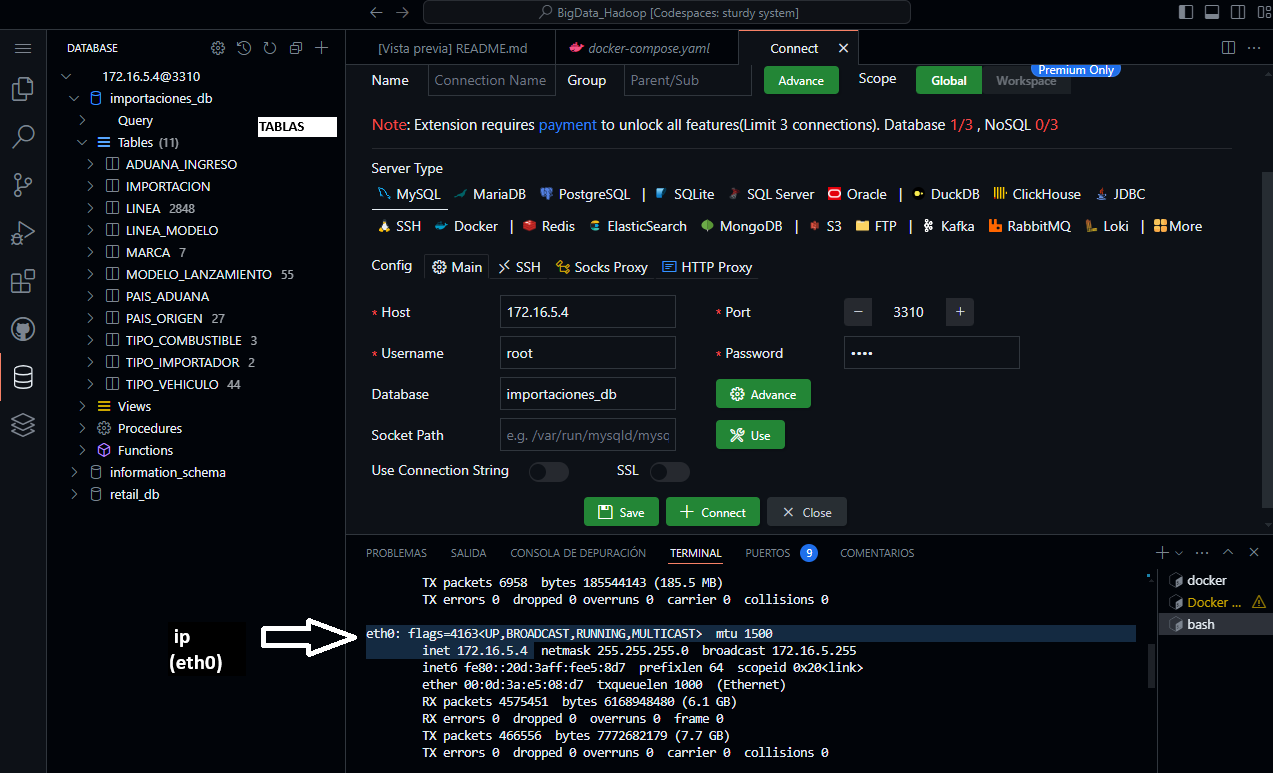
MySQL
Este contenedor contiene una base de datos llamada importaciones_db y consta de las tablas que se verá en al imagen.
Las credenciales para conectarnos a nuestra base de datos es misma que encontrar en el archivo: mysql/Dockerfile:
- user: root
- pass: root
- port: 3310
Ejecutar ifconfig en terminal para obtener la ip (eth0)
Hadoop
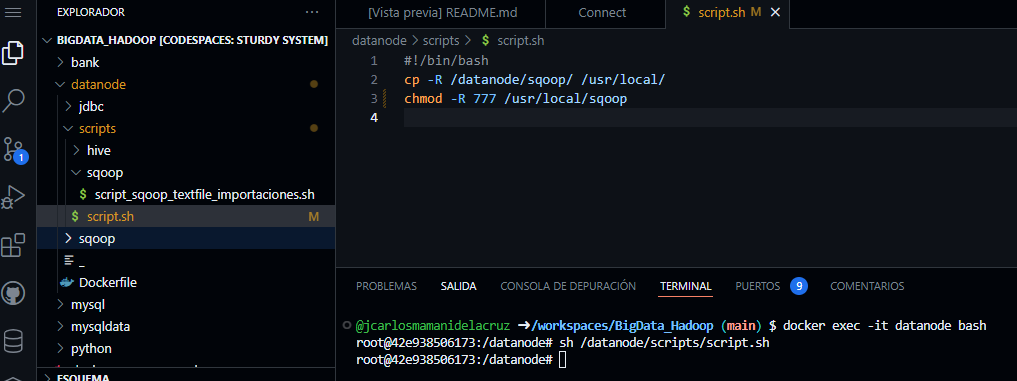
Para poder trabajar con hadoop ingresamos al contenedor del datanode.
- Abrimos un terminal nuevo y ejecutamos lo siguiente:
docker exec -it datanode bash
- Asi para cada contenedor con el que queremos trabajar.
- Para utilizar sqoop en el datanode debemos ejecutar lo siguiente:
sh /datanode/scripts/script.sh
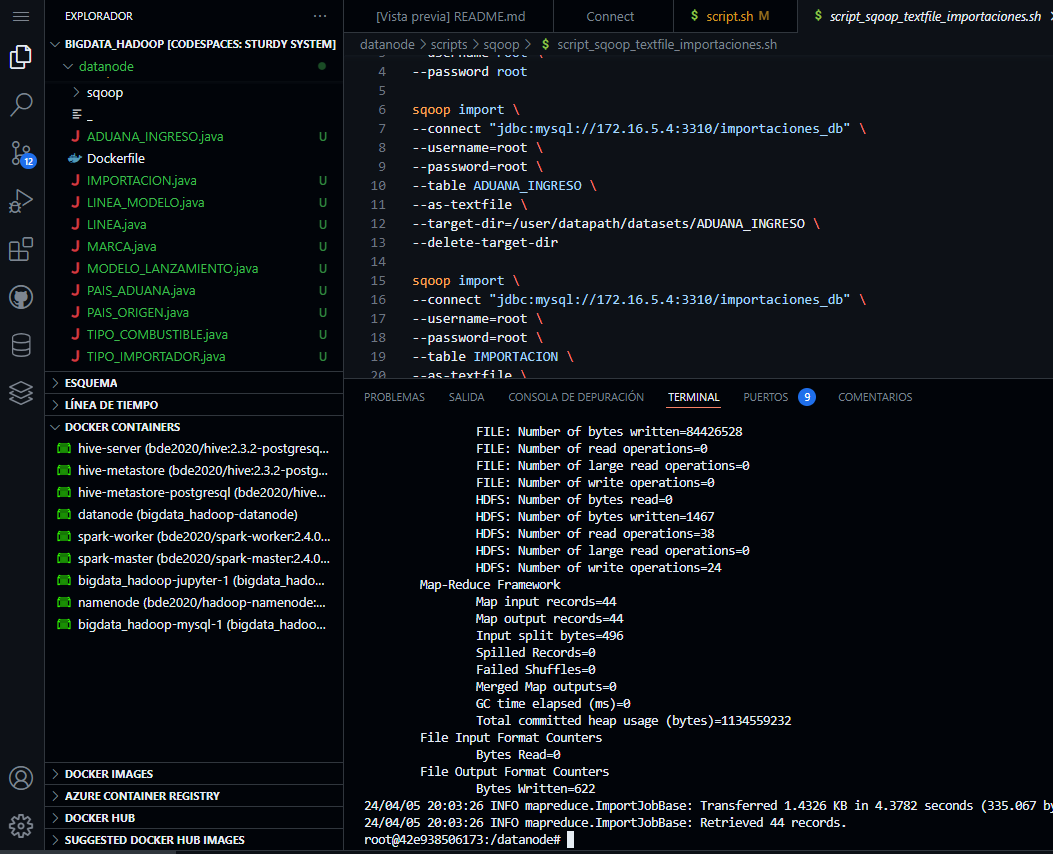
 - Para exportar las tablas de la base de datos importaciones_db con sqoop al HDFS de hadoop ejecutar lo siguiente:
sh /datanode/scripts/sqoop/ script_sqoop_textfile_importaciones.sh
- Para exportar las tablas de la base de datos importaciones_db con sqoop al HDFS de hadoop ejecutar lo siguiente:
sh /datanode/scripts/sqoop/ script_sqoop_textfile_importaciones.sh
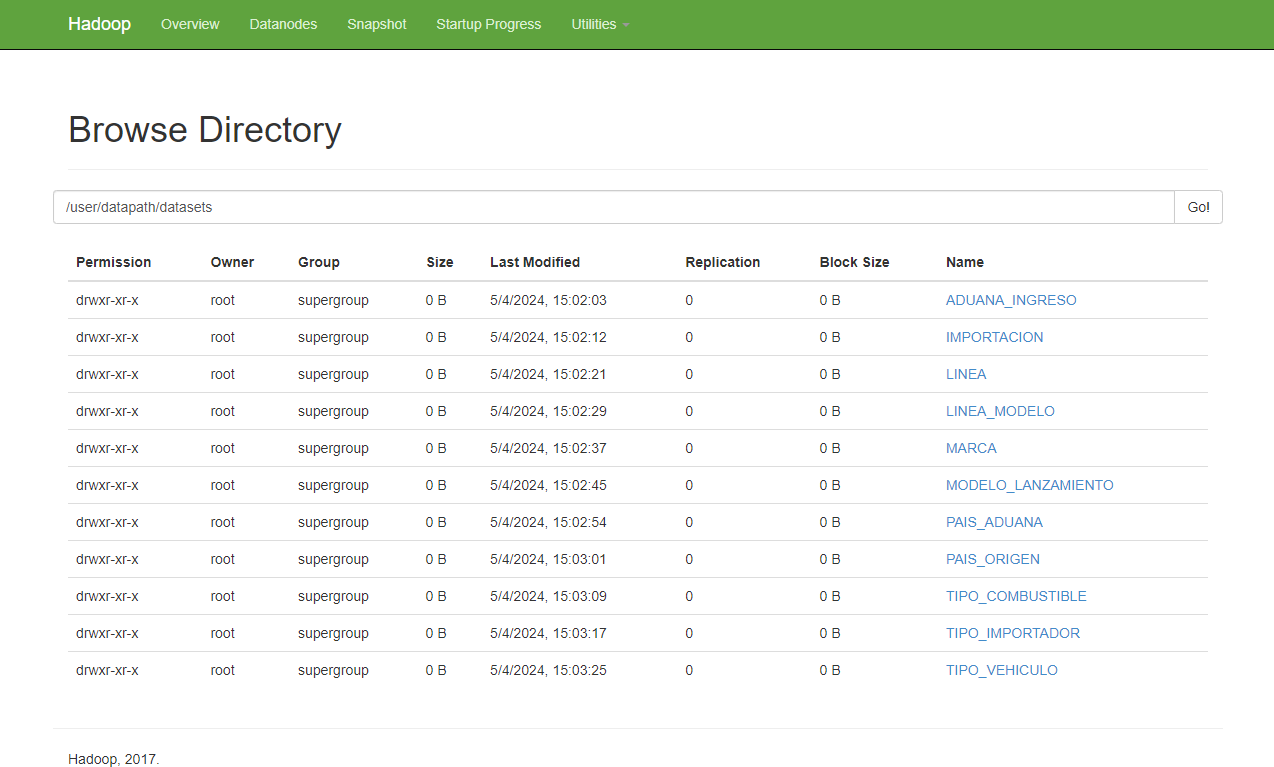
 - Para visualizar los ficheros en el HDFS de hadoop:
- Para visualizar los ficheros en el HDFS de hadoop:
Hive
Para poder trabajar con hive ingresamos al contenedor del hive-server.
- Abrir un terminal y copiar el archivo hive.hql a hive-server
docker cp datanode/scripts/hive/ hive_importaciones_db.hql hive-server:/opt
- Abrimos un terminal nuevo y ejecutamos lo siguiente
docker exec -it hive-server bash
Para crear tablas externas en base a los datos importados con sqoop ejecutamos los siguientes pasos:
-En el terminal de hive-server ejecutamos lo siguiente para crear las tablas
hive -f /opt/hive.hql
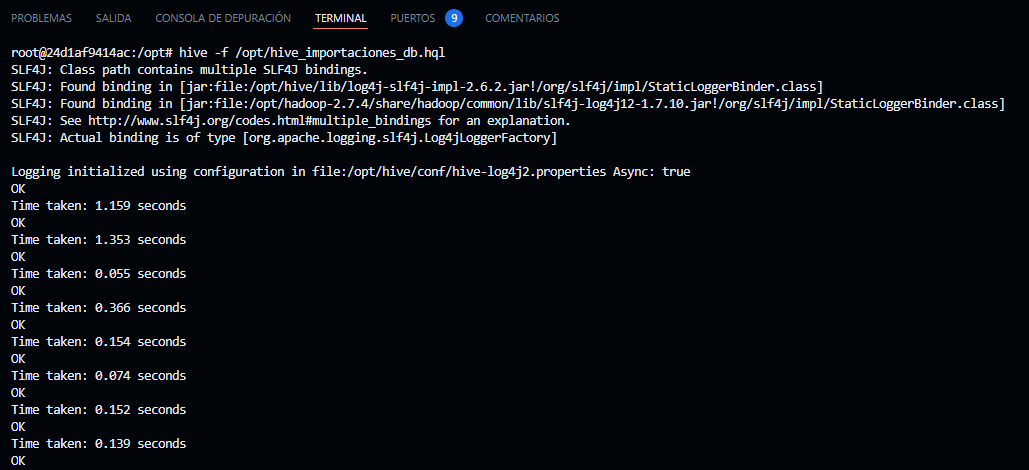 - En el terminal de hive-server ejecutamos lo siguiente para listar las base de datos de hive
hive
- En el terminal de hive-server luego de haber ejecutado el comando hive ejecutamos lo siguiente
show databases;
use importaciones_db;
show tables;
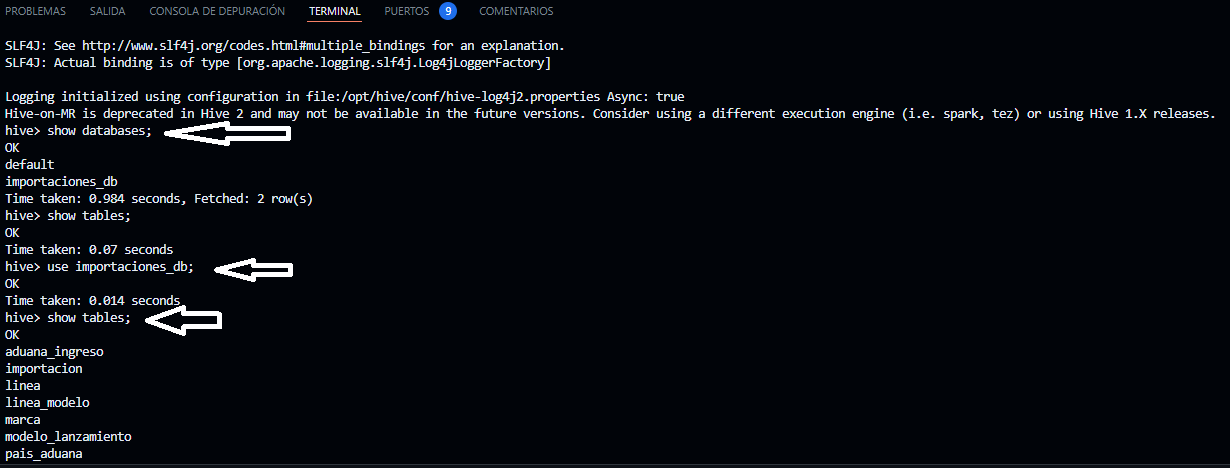
- En el terminal de hive-server ejecutamos lo siguiente para listar las base de datos de hive
hive
- En el terminal de hive-server luego de haber ejecutado el comando hive ejecutamos lo siguiente
show databases;
use importaciones_db;
show tables;
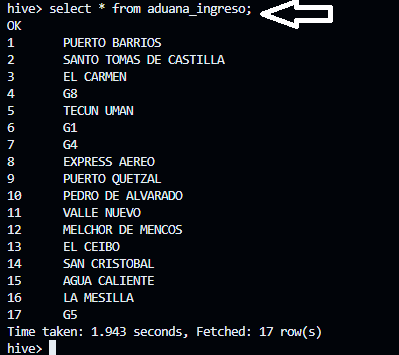
 - En la misma terminal de hive-server ejecutamos lo siguiente comando para verificar el contenido de las tablas en hive;
select * from aduana_ingreso;
- En la misma terminal de hive-server ejecutamos lo siguiente comando para verificar el contenido de las tablas en hive;
select * from aduana_ingreso;
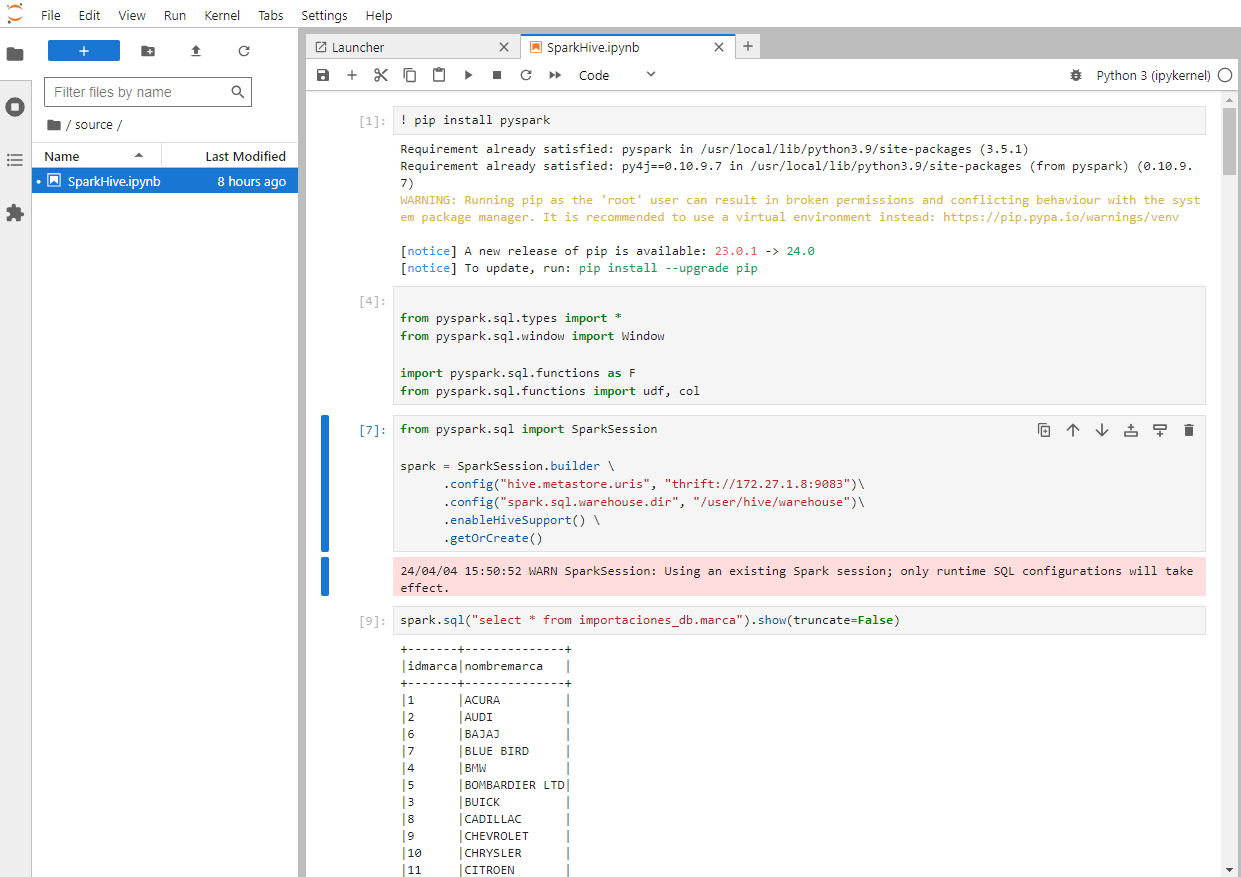
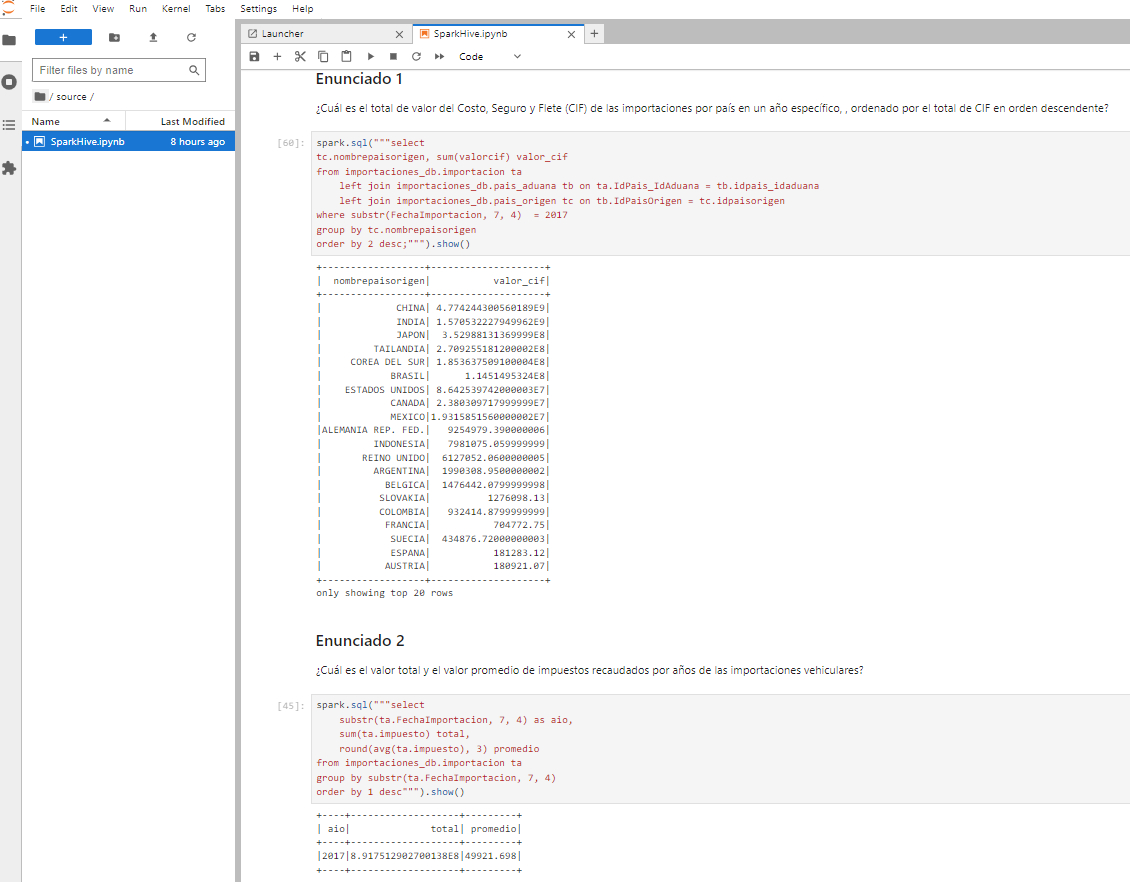
Conexión a Hive en Hadoop utilizando Spark
Para trabajar con las tablas migradas de importaciones_db en Hadoop, utilizaremos Spark. A continuación, se detallan los pasos para conectarte a Hive y realizar análisis de datos utilizando PySpark desde Jupyter Notebook:
Una vez que los contenedores estén en funcionamiento, puedes utilizar Docker Explorer en Visual Studio Code para acceder a los puertos expuestos por los contenedores acá ubicaremos el puerto 8200 que es el puerto expuesto para nuestro Jupyter Notebook
 Una vez que hayas abierto Jupyter Notebook utilizando Docker Explorer, encontrarás un archivo SparkHive-checkpoint.ipynb. Para acceder al archivo que contiene los códigos para conectarse a Hadoop y Hive, así como las queries utilizadas para el análisis de datos.
Una vez que hayas abierto Jupyter Notebook utilizando Docker Explorer, encontrarás un archivo SparkHive-checkpoint.ipynb. Para acceder al archivo que contiene los códigos para conectarse a Hadoop y Hive, así como las queries utilizadas para el análisis de datos.